[PAPER] Qwen3-VL Technical Report
About Problem
Idea
기존의, Qwen2.5-VL의 경우 임베딩 차원을 Temporal(t) / Horizontal(h) / Vertical(w) 그룹으로 chunking하였는데, 이러한 방식이 주파수 스펙트럼의 불균형을 초래하고, 긴 비디오에 대한 이해 능력을 저해되었다.
따라서, t, h, w를 저주파 및 고주파 대역 전반에 균등하게 분포시키는 interleaved 방식의 M-RoPE를 적용하였다.
또한, DeepStack과 Explicit video timestamp를 도입하였다.
Key Previous Papers
- SigLIP-2 : SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features [PAPER]
- CoMP : Continual Multimodal Pre-training for Vision Foundation Models [PAPER]
- DeepStack : [PAPER]
- Revisiting Multimodal Positional Encoding in Vision-Language Models [PAPER]
- TimeMarker : A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability [PAPER]
- Qwen3 : Qwen3 Technical Report [PAPER]
Model Architecture
보통의 LVLMs들은 LLM과 Vision Encoder로 구성된다. Qwen2-VL 또한, 해당 구성을 사용하였다.
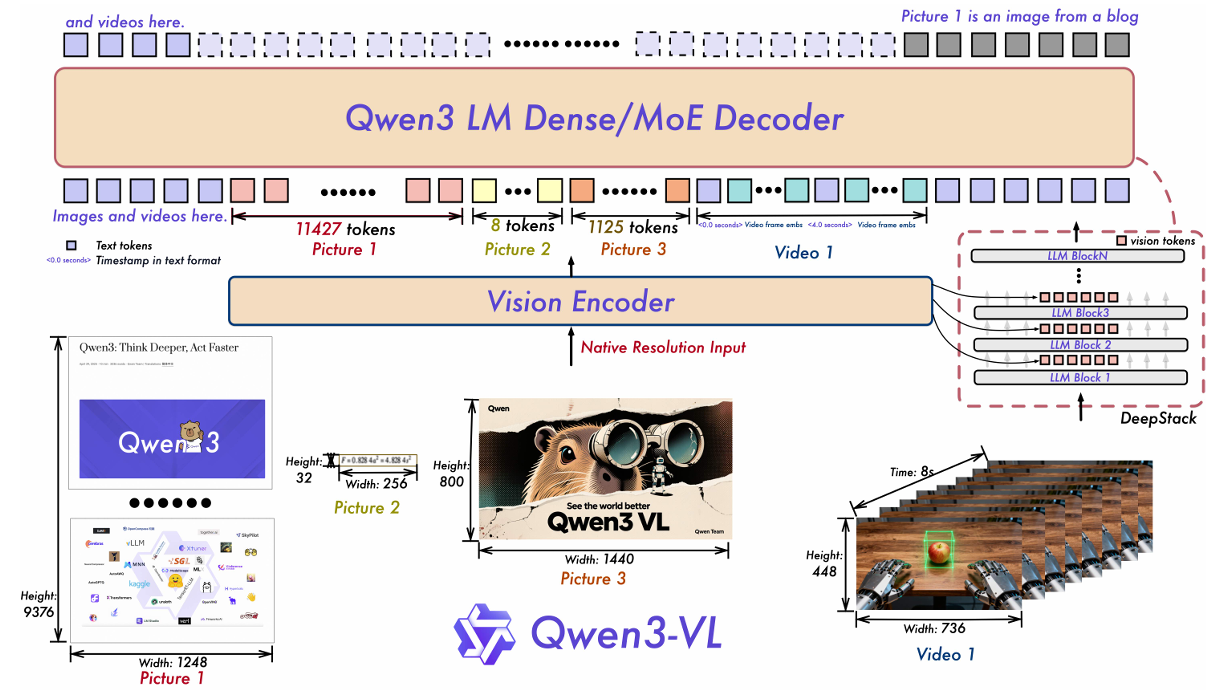
LLM
Qwen3-VL의 LLM은 이름에서도 유추할 수 있다시피, Qwen3 LLM을 사용하였고, 4개의 Dense 모델(2B,4B,8B,32B)과 2개의 MoE 모델(30B-A3B,235B-A22B)에 대해서 학습을 진행하였다.
MLP-based Vision-Language Merger
단순 MLP 구조로 이루어져 있으며, 이미지/비디오의 feature sequence가 길어질 때 발생하는 문제를 해결하기 위함이다.
또한, Deepstack에서 아이디어를 얻어, Vision Encoder의 서로 다른 3 layer에서 visual token을 추출하여 LLM의 초기 layer에 더해주었다.
Vision Encoder
Qwen3-VL의 Vision Encoder는 지난 Qwen2-VL에서 사용하였던 DFN에서 파생된 ViT를 사용하였으나, Qwen3-VL에서는 SigLIP-2를 사용하였다. 물론, SigLIP-2를 그대로 사용하지는 않았고, 2D-RoPE를 도입하고, CoMP(Continual Multimodal Pre-training for Vision Foundation Models)를 도입하였다.
Explicit video timestamp
기존, Qwen2.5-VL에서 모델에 Temporal한 정보를 주입하기 위해 사용한 시간-동기화된 M-RoPE는 아래의 한계를 가졌다.
- Temporal Position ID를 절대 시간에 대해 직접 연결하여, 긴 비디오에 경우, ID가 지나치게 크고 희소하게 생성되어, long temporal context를 이해하는 능력이 저하되었음
- 효과적인 학습을 위하서는 다양한 fps에 대해 광범위하고 균등하게 분포된 샘플링이 필요하여, 데이터 구축 비용을 크게 증가시킴
따라서, 각 비디오의 temporal patch 앞에 <3.0 second>와 같은 형식화된 timestamp를 추가하였다.