[PAPER] Qwen2.5-VL Technical Report
About Problem
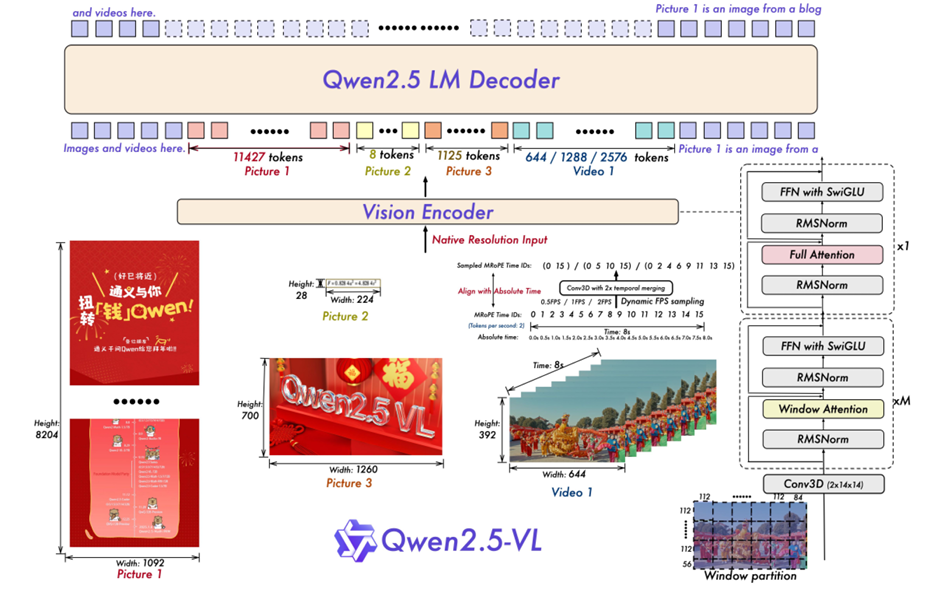
Model Architecture
보통의 LVLMs들은 LLM과 Vision Encoder로 구성된다. Qwen2.5-VL 또한, 해당 구성을 사용하였다.
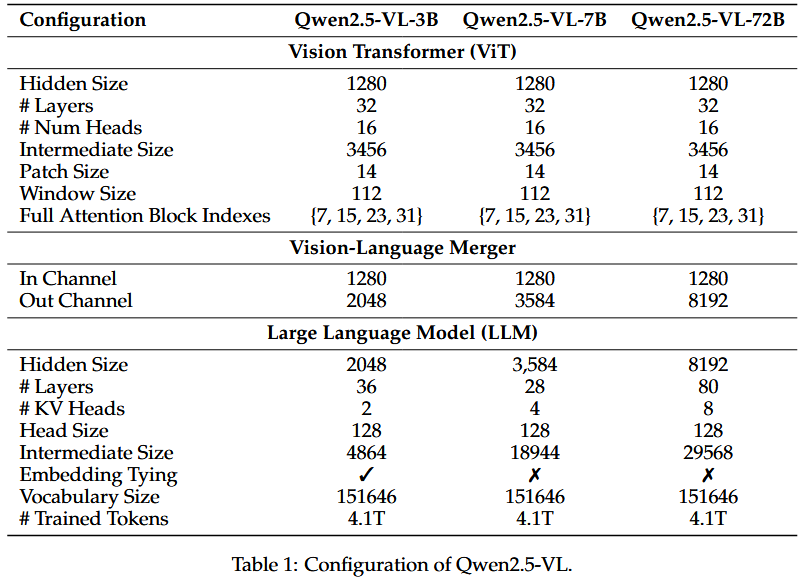
자세한 Configuration은 다음과 같다.
LLM
Qwen2.5-VL의 LLM은 이름에서도 유추할 수 있다시피, Qwen2.5 LLM을 사용하였고, 3개의 size(3B,7B,72B)에 대해서 학습을 진행하였다.
MLP-based Vision-Language Merger
단순 MLP 구조로 이루어져 있으며, 이미지/비디오의 feature sequence가 길어질 때 발생하는 문제를 해결하기 위함이다.
Vision Encoder
Qwen2.5-VL의 Vision Encoder는 지난 Qwen2-VL과 달리, window attention을 사용한 것이 특징이다.
이는, 다양한 크기의 이미지를 추론하기 위해 필요한 부하를 $O(N^2)$ 에서 $O(N)$ 으로 증가하도록 설계하였다.
저자들은 최대로 112x112 pixel (8x8 patch)를 하나의 window로 보았다.
또한, Qwen2-VL과 같이 2D-RoPE를 사용하였다.
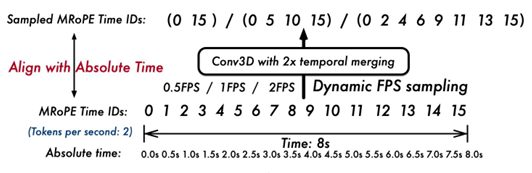
Multimodal Rotary Position Embedding Aligned to Absolute Time
Qwen2-VL에서는, M-RoPE의 temporal position에 대한 ID값이 입력 frame에 종속되어, 사건의 절대적인 발생 시점을 잘 반영하지 못했다. 따라서, 기존의 frame 개수만큼 Temporal ID를 증가시키는 방법이 아니라, 절대적인 시간에 따라 Temporal ID를 증가시키는 방향으로 설계하였다.