[PAPER] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
About Problem
Idea
text-to-text 분야에서는 autoregressive(GPT) 또는 masked language modeling(BERT) 등의 LLM들이 텍스트 생성이나 요약, QA 등 여러 텍스트 관련 task에 있어서 훌륭한 성과를 보여주고 있다.
그러나, 이런 모델은 PURE-TEXT WORLD에 한정되어 있기에, 인간이 느끼는 흔한 감각들을 느끼지 못하고, 이는 곧 모델의 활용에 큰 제약을 만들게 된다.
이러한 흐름에서, 인간의 여러 감각 중 시각(Vision)의 영역에서도 해당 모델을 적용해보고자 하는 시도가 있었고, 그런 시도의 연장선이 닿은 곳이 LVLMs(Large Vision Language Models)이다.
그러나, 그 시대의 Open-sourced model은 Openai 등 기업이 closed-source로 가지고 있는 모델에 비해 성능이 떨어졌고, 이로 인하여 오픈 소스 커뮤니티에서의 탐색과 적용의 어려움이 컸다.
그래서, Alibaba Group에서는 고성능이면서 다재다능한 Foundation Model을 만들고자 했고, 그러한 결과가 Qwen-VL모델이다.
Key Previous Papers
- Qwen : Introducing qwen-7b: Open foundation and human-aligned models [PAPER]
- ViT : An image is worth 16x16 words: Transformers for image recognition at scale [PAPER]
Model Architecture
보통의 LVLMs들은 LLM과 Vision Encoder로 구성된다. Qwen-VL도 예외는 아니며, 추가로 Position-aware Vision-Language Adapter가 추가되었다.
LLM
Qwen-VL의 LLM은 이름에서도 유추할 수 있다시피, Qwen-7B을 사용하였다.
Vision Encoder
Qwen-VL의 Vision Encoder는 ViT(Vision Transformer)를 사용하였고, Pretrained Weight는 Openclip’s ViT-bigG를 사용하였다.
Position-aware Vision-Language Adapter (VL-Adapter)
ViT는 Patch 단위로 image를 embedding 하게되며, 이 과정에서 [CLS] token만을 사용하는 것이 아니라면, image size에 따라 patch의 개수가 바뀌게 된다. (#_of_patches, embedding dimension) 이렇게 바뀐 patch의 개수는 embedding sequence 길에 영향을 미칠 것이다.
작은 이미지의 경우에는 문제가 크게 되지 않겠지만, 지나치게 큰 이미지를 받게 되면, 긴 embedding sequence가 발생하게 될 것이고, 이것은 효율성에 문제를 발생시킬 수 있다. 따라서, 저자들은 Position-aware Vision-Language Adapter를 추가하여 256개의 token으로 token의 수를 줄였다. (#_of_patches, embedding dimension) -> (256, embedding dimension)
해당 모듈은 single-layer cross-attention 구조로 구성되어 있다.
QUERY : Trainable embedding vector
KEY : image embedding features from Image Encoder (ViT)
VALUE : Key와 동일 (논문에 명시적 언급은 없었으나, 관행상 Key와 동일할 것으로 추정됨)
+ : 2D absolute positional embedding을 query-key pairs에 추가함
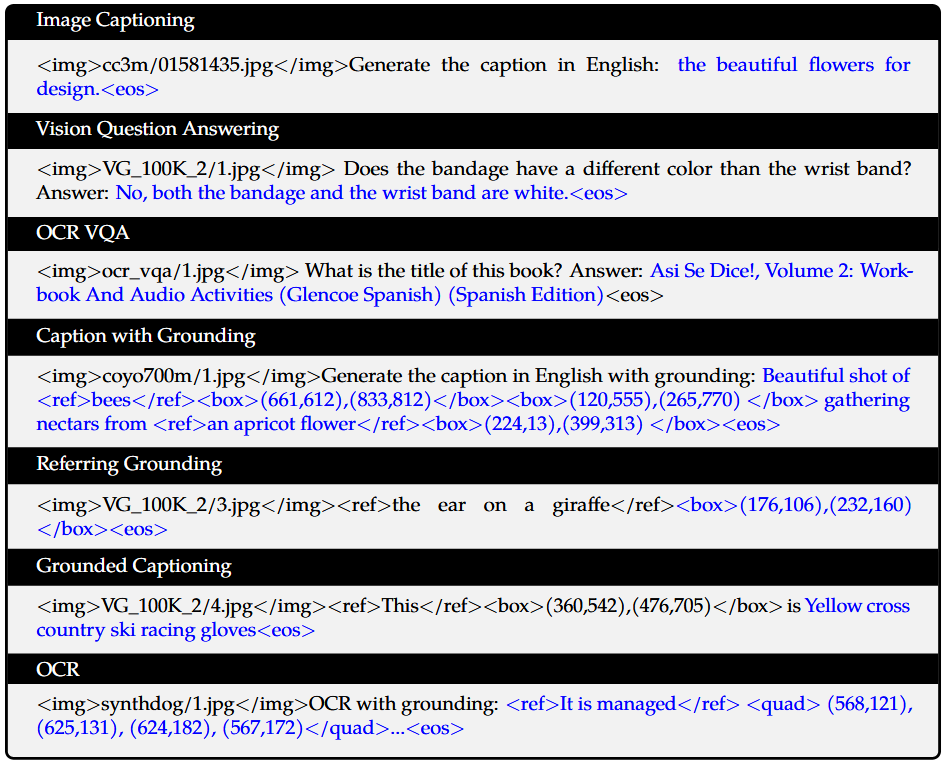
Token Structure
General tokens
Image feature input token과 Text feature input token을 구분하기 위해서 아래의 <img> token과 </img> token을 사용하였다.
<img> : image start special token
</img> : image end special token
<eos> : end of sequence token