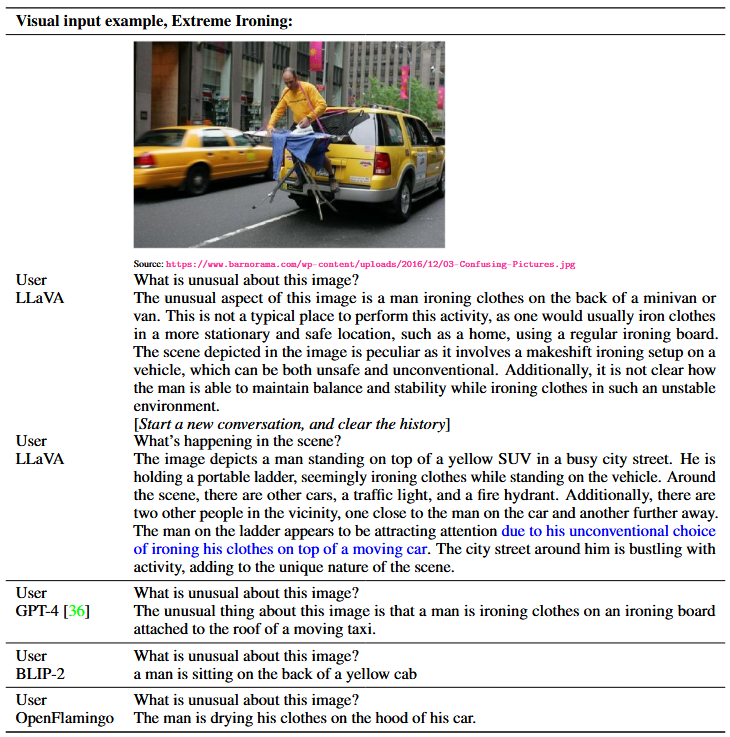
[PAPER] Visual Instruction Tuning
About Problem to solve
Background
“오감”. 인간의 다섯 감각을 이야기하며, (시각, 청각, 후각, 미각, 촉각)으로 구성되어 있다. 우리는 이런 오감을 통해 세상을 이해하고 소통한다. 이런 오감은 각 요소마다 다른 특성을 가지고 있는데, 그 중 가장 많이 연구된 요소이자, 가장 보편적인 요소는 바로 “시각(Vision)” 이다.
이러한 맥락에 따라, 이미지에 대한 설명을 모델에게 알려줄 필요가 있었고, 따라서, language-augmented foundation vision model에 대한 관심이 생기고 있다. 그러나, 이 논문 이전의 모델들은 텍스트를 이미지 내용을 기술하는 정도로만 사용하기에, 사용자 지시에 대한 상호작용성과 적응성이 제한될 수 밖에 없었다.
이에, 상호작용성과 적응성이 뛰어난 LLM을 Vision 분야에 사용하고자 하였고, 그러한 시도들은 크게 다음과 같이 분류할 수 있다.
- Multimodal Instruction-following Agents
- Instruction Tuning
그러나, 해당 Multimodal Instruction-following Agents의 경우, 여러 세분화된 task 별로 각자의 모델이 필요하다는 단점이 있으며, Instruction Tuning의 경우 Vision-Language Instruction data로 tuning되지 않았기에, 기존 LLM보다 성능이 낮았다.
따라서 저자들은 다양한 task를 수행할 수 있는 end-to-end trained models을 Vision-Language Instruction data로 tuning하여, 기존 LLM과 성능 격차를 해소하고자 하였다.
Idea
LAION등의 데이터셋은 bbox와 caption을 포함하고 있다. 그렇다면, 우리는 이 bbox와 caption을 Instruction으로 바꾸어야 한다. 따라서, 저자들은 GPT-4를 사용하여 “TEXT”로 bbox, caption을 넣어주고, (Conversation, Detailed description, Complex Reasoning) 3개의 instruction을 만들도록 하였다. 예시는 다음과 같다.

Model Architecture
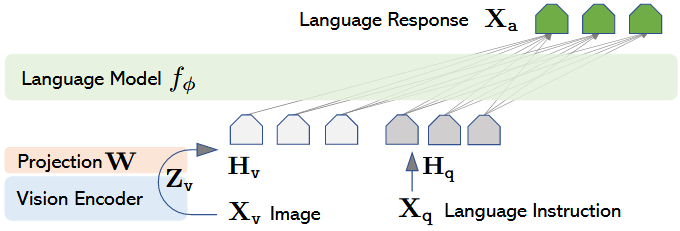
모델의 구조는, 이전의 Q-former나 Flamingo 보다 단순한 위와 같은 구조를 사용하였다. input image에 대해, CLIP-ViT-L/14를 사용하여 embedding을 뽑고, 그것을 projection matrix를 통해 차원을 축소한다. CLIP-ViT-L/14에서 고정된 사이즈로 resize하기 때문에, token의 개수는 변하지 않는다.
\[\begin{aligned} \text{Image } X_v, \\ \text{Multi turn Conversation } (X^1_Q,X^1_A,\cdots,X^T_Q,X^T_A)\\ \mathbf{x}^{t}_{\text{instruct}} = \begin{cases} \text{Randomly choose } [\mathbf{x}_q^{1}, \mathbf{x}_v] \text{ or } [\mathbf{x}_v, \mathbf{x}_q^{1}], & \text{the first turn } t = 1 \\ \mathbf{x}_q^{t}, & \text{the remaining turns } t > 1 \end{cases} \\[15pt] \text{With using auto-regressive objective } \\ p(\mathbf{X}_a \mid \mathbf{X}_v, \mathbf{X}_{\text{instruct}}) = \prod_{i=1}^{L} p_{\theta}\!\left( x_i \mid \mathbf{X}_v,\, \mathbf{X}_{\text{instruct},<i},\, \mathbf{X}_{a,<i} \right) \\[10pt] \text{When Sequence Length L, Probability of target Answer } X_a, \text{trainable paramters } \theta, \\ X_{instruct,<i} \text{ and } X_{a,<i} \text{ instruction and answer tokens in all turns before i position} \end{aligned}\]Training Methods
Pre-training for Feature alignment
여러 (image,caption) dataset을 training에 사용하는 step으로, 하나의 (image,caption) pair를 single turn으로 취급하여 학습한다. $X_q$ 는 무작위로 sampling된 설명을 요청하는 지시문이고, 정답 라벨은 원본 캡션을 사용한다.
이 step에서는, Vision encoder와 LLM을 모두 freeze하고, projection matrix W만을 학습한다. 즉 $ \theta = W $ 이다.
이 과정은 image feature를 LLM의 word embedding space에 정렬하는 과정으로 이해할 수 있겠다.
Fine-tuning End-to-End
위에서 GPT를 사용하여 제작한, instruction dataset을 training에 사용하는 step으로, Vision Encoder를 freeze하고, LLM과 Projection Matrix를 학습한다. 즉 $\theta = (W,\phi)$ 이다.
Result